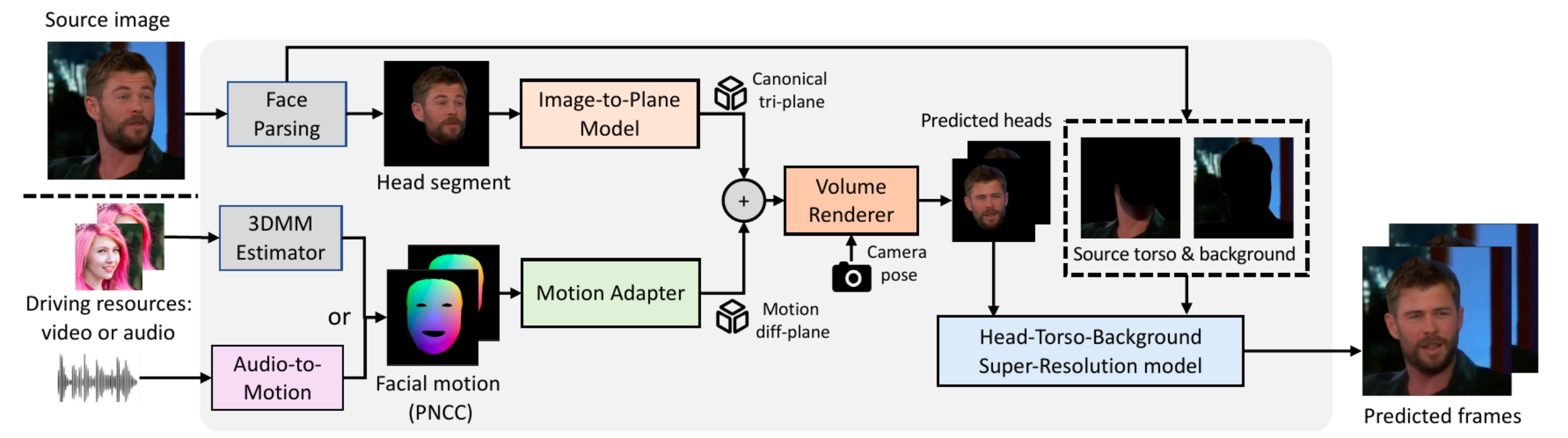
1. Video-Driven Comparison
We compare with Face-vid2vid (CVPR 2019 Oral), OTAvatar (CVPR 2023), and HiDe-NeRF (CVPR 2023). The comparison shows that our Real3D-Portrait overcomes the challenges faced by these methods and achieves one-shot realistic talking video generation.